記事更新日: 2021/08/21



ハローエンジニア!みなさんは「CSVファイル」をご存じでしょうか?
住所録アプリや家計簿アプリなどのエクスポートファイルとして、見たことがある方もいるのではないでしょうか。
ほかにも業務アプリなど、広く使われているCSVファイルですが、「どんなファイルですか?」と聞かれたら説明できるでしょうか?
エンジニアの仕事でも登場するCSVファイル。何気なく使っていても標準仕様ってどうなっているのか気になりますよね。
「CSVファイル」とはいったい何か。どのような仕様のファイルなのかをまとめてみました。
このページの目次

CSVファイルとは、いくつかのテキストデータを、カンマ「,」で区切って並べたテキストファイルです。
CSVは、Comma-Separated Values(カンマで区切られた値)の略語で、「カンマ区切りで並べた値」を意味します。
具体的には次のようなテキスト形式をCSV、このようなテキストが保存されたファイルをCSVファイルと呼びます。
スズメ,女性,4区
ハクロ,男性,4区
メンタ,女性,2区
ジア,男性,3区
シンプルなテキスト形式であることに加えて、Excelのような表計算ソフトで扱えるため、様々なサービスやソフトウェアでサポートされています。

CSVにはもうひとつ、Character-Separated Values(文字で区切られた値)の略語もあります(以下、カンマ区切りと区別するため「広義のCSV」と呼びます)。
広義のCSVでは、カンマ区切りのCSVとそれに類する、タブ区切りのTab-Separated Values (TSV)、半角スペース区切りのSpace-Separated Values (SSV) 、セミコロン区切りの Semicolon-Separated Values (SSV)などをまとめて指します。
広義のCSVと他の書式の関係は次のように表せます。
Character-Separated Values (CSV; 文字区切り)
┣ Comma-Separated Values (CSV; カンマ区切り)
┣ Tab-Separated Values (TSV; タブ区切り)
┣ Space-Separated Values (SSV; スペース区切り)
┗ Semicolon-Separated Values (SSV; セミコロン区切り)
広義のCSVは、ライブラリやツールなど、汎用的な場面で用いられます(PowerShellのConvertTo-Csvなど)。
転じて一般にも使われることがあるので、「CSV」と遭遇した場合はどちらの意味で使われているか文脈から判断しましょう。
ちなみに、セミコロン区切り(Semicolon-Separated Values; SSV) の場合は、次のようになります。
スズメ;女性;4区
ハクロ;男性;4区
メンタ;女性;2区
ジア;男性;3区
個人的な経験ではセミコロンのCSVファイルは見たことがありますが、タブとスペースは見たことがありません。身近なTSVとしては、ExcelやHTMLのtableタグのコピーデータなどで利用されています。このあたりの分布は分野や業界にもよりますね。
ちなみに、広義のCSVを説明する理由は、知っているとCSVに関わる紛争の3割は解決するためです(当社比)。

CSVはデータ交換/変換のデファクトスタンダードとして、様々なベンダーおよびソフトウェアで広く扱われてきた一方、長らく標準的な仕様はありませんでした。
そんななか、2005年10月にRFC 4180「Common Format and MIME Type for Comma-Separated Values (CSV) Files」がIETFから公開されました。
タイトルを日本語に訳すと「CSVファイルの一般的書式とMIMEタイプ」という意味です。
このRFC4180は、インターネットコミュニティに情報を提供することを目的に制定されており、インターネットの標準仕様は何ら定めるものではないとしています。Category (文書分類) も「Standards Track (標準化過程)」ではなく「Informational(情報)」です。
つまり、CSVファイルの標準化された仕様を示すものではありません。
とはいえRFC4180は、CSVについて包括的に定めた初めての国際文書で、ほとんどの実装が追随可能と考えられる書式が記載されています。
そのため、CSVを理解する参考として「国際標準」仕様として読み解きます。
RFC4180で示されているCSV形式の定義は次の7項目です。
補足:「フィールド」と「レコード」
RFC4180では特に説明なく登場した「フィールド」と「レコード」ですが、これらはデータベースに関する用語です。
フィールドは、1つ1つのデータ値を意味する言葉です。テーブル表現では「セル」に相当します。
レコードは、横に連続したフィールドのひと固まりを意味する言葉です。テーブル表現では「行」に相当します。
図にすると次のようになります。
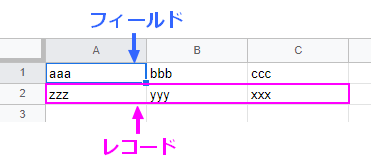
この図では、各セルにあたる「aaa」、「bbb」、「ccc」、「zzz」、「yyy」、「xxx」がそれぞれフィールドです。
そして、各行にあたる「aaa,bbb,ccc」と「zzz,yyy,xxx」がレコードとなります。
(1) 各レコードは、改行(CRLF)を区切りとして分割された行に配置される。

ナガヤン
例えば、次のように「aaa,bbb,ccc」と「zzz,yyy,xxx」の2つのレコードを改行で区切って配置できます。
aaa,bbb,ccc <CRLF>
zzz,yyy,xxx <CRLF>
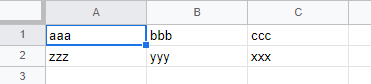
レコードは、Excelなどのテーブル表示での1行と同じです。
(2) ファイル末尾のレコードの終端には、改行はあってもなくてもよい。
ナガヤン
例えば、次のように最後の改行を省略することができます。
aaa,bbb,ccc <CRLF>
zzz,yyy,xxx
改行があってもなくても、表現上は同じです。
(3) ファイルの先頭には、オプションとして、通常のレコード行と同一の書式を持つヘッダ行が存在してもよい。このヘッダは、各フィールドの名称を保持し、各レコードが持っているのと同じ数のフィールドを持つ。
ナガヤン
例えば、次のようにヘッダ行は、各レコードと同じ3つのフィールド(値)を持ち、それぞれのフィールドに対応する名前(列名)が保持されています。
field_name1,field_name2,field_name3 <CRLF>
aaa,bbb,ccc <CRLF>
zzz,yyy,xxx <CRLF>
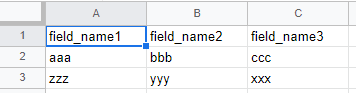
ヘッダ行がある場合、先頭に1行追加されます。
(4) ヘッダと各レコードは、カンマで区切られた1つ以上のフィールドを含む。各行が保持するフィールドの数は、ファイル全体を通じて同一であるべきである。スペースはフィールドの一部とみなす。最後のフィールドはカンマで終わってはならない。
ナガヤン
例えば、次のようにレコードはカンマで区切られた1つ以上のフィールドを持ち、最後のフィールドはカンマで終わりません。
aaa,bbb,ccc

「ccc」がレコード最後のフィールドです。
(5) 各フィールドは、それぞれ二重引用符で囲んでも囲まなくてもよい。フィールドが二重引用符で囲まれていない場合、そのフィールドの値には、二重引用符が含まれてはいけない。
ナガヤン
例えば、次のように二重引用符で囲んでいるレコードと二重引用符で囲まないレコードを混在させてもOKです。
"aaa","bbb","ccc" <CRLF>
zzz,yyy,xxx
二重引用符がない場合と、表現上は同じです。
(6) 改行(CRLF)、二重引用符、カンマを含むフィールドは、二重引用符で囲むべきである。
ナガヤン
例えば、「b<CRLF>bb」といった改行を含むフィールドは、次のように二重引用符で囲んでいれば1つのフィールドとして扱えます。
"aaa","b <CRLF>
bb","ccc" <CRLF>
zzz,yyy,xxx
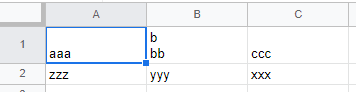
改行も二重引用符で囲んでいれば、フィールドの一部として表現されます。
ナガヤン
ちなみに、「改行をフィールドに含めることができる」は、意外と認知されていません。
ツールなどでもサポートされてない場合がありますのでご注意ください(例:「Rainbow CSV」)。
(7) フィールドが二重引用符で囲まれている場合、フィールドの値に含まれる二重引用符は、その直前にひとつ二重引用符を付加して、エスケープしなければならない。
ナガヤン
例えば、「b”bb」といった改行を含むフィールドは、次のように二重引用符でエスケープしていれば1つのフィールドとして扱えます。
"aaa","b""bb","ccc"
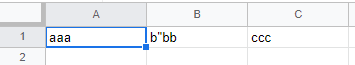
エスケープされた二重引用符は、フィールドの文字列として扱われます。

RFC4180は「ほとんどの実装が追随可能」として公開されましたが、実際にはプロジェクトや状況によって異なるCSVの仕様が定められることがあります。
そのため、円滑に開発を進めるためにも、トラブルを回避するためにも、次の6点を事前に取り決めておきましょう。
「1. 文字コード」「2. 改行コード」は、CSVに限らず、テキストファイルを扱う場合に必ず取り決めるべき項目です。
項目5と6は、すでにCSVの仕様が決まっていれば、この聞き方でOKです。
これからCSVの仕様を定める場合は「二重引用符、カンマ、タブ、改行が、列名またはデータに入ってきますか?」と確認しておきましょう(経験上たいがいは入ってきます)。
そのうえで二重引用符で囲む話、エスケープの仕方などを取り決めておきます。
これらの取り決めは、発注側も受注側も曖昧にしやすいため、これらに起因する話はCSV苦労話としてよく見受けられます。
SJISのCSVを送ってくるやつを刺す仕事をしています
— medy.nim@旅するCTO (@dumblepytech1)May 28, 2021
日本語のCSVといえば、SJISのタブ区切りって相場が決まってるんだ!(Excelで一度開いて上書き保存したファイル)
— 氷穂(ひすぃ)お酒(燃料)が足りない (@IcEar)June 22, 2021
csvってセル内改行できるのか
— うたこ (@digi_loli)August 5, 2021
CSVファイルの処理はセル内に改行とかカンマを含むデータを処理するかどうかで難度が違いすぎる
— F.T.T.H(敬意・感謝・絆) (@FTTH)July 10, 2021
いや、あまりクソみたいなフォーマットのCSVファイル見た事ないな…。まぁ、一ファイル中にSJIS、EBCDIC、UTF-8の文字コードの文字が混在、データのカンマがエスケープが未実施、データの先頭行が省かれてるなんてこともあったな。1番キツかったのは先頭行が省かれてた時かな。全然気づかなかった!!
— Ash (@Contoso2021_)June 29, 2021
CSV形式の仕様と実運用における注意点を説明しました。
CSVは広く使われる一方で、説明資料が少なく、プロジェクトごとに方言があるので、暗中模索になりがちです。
RFC4180の「国際標準」仕様を軸に、自分の扱うCSVはどのようなクセがあるのか見極めて、適切な取り扱いをしていきましょう。